Or how to seriously annoy intelligent people by telling deliberate lies.
A story about renewable energy has been doing the rounds within my social media circles, Â and especially on FaceBook. It is an article from The Independent newspaper that has been eagerly shared by those with an interest in the subject. Â The headline reads “Britain just managed to run entirely on renewable energy for six days”.
This is what it looks like on FaceBook:

My first thought was that, obviously, this was complete nonsense. Had all of the petrol and diesel powered cars in Britain been miraculously converted to electric and hundreds of charging points installed overnight? I think that we would have noticed, or perhaps I am living in a parallel universe where such things have not yet happened. Â So I assumed that the writer of the article, or the sub-editor, Â had done what some journalists are prone to do, which is to use the terms energy and electricity interchangeably. Even if they meant “electricity” Â I still found the claim that all of our electricity had been generated from renewable sources for six days difficult to believe.
Look below the  headline and you will see that the first sentence says “More than half of the UK’s electricity has come from low-carbon sources for the first time, a new study has found.” That is more like it. Rather than “run entirely on renewable energy” we now have “half of the UK’s electricity has come from low-carbon sources” [my emphasis in both quotes]. But why does the title make the claim when straightaway the text tells a different story? And low carbon sources are not necessarily renewable, for example nuclear. As I keep telling people on my workshops, always click through to the original article and read it before you start sharing with your friends.
The title on the source article is very different from the facebook version as is the subtitle.

We now have the title “Half of UK electricity comes from low-carbon sources for first time ever, claims new report”, which is possibly more accurate. Note that “renewable” has gone and we have “low carbon sources” instead. Also, the subtitle muddies the waters further by referring to “coal- free”.
If you read the article in full it tells you that “electricity from low-emission sources had peaked at 50.2 per cent between July and September” and that happened for nearly six days during the quarter. Â So we have half of electricity being generated by “low emission sources” but, again, that does not necessarily equate to renewables. The article does go on to say that the low emission sources included UK nuclear (26 per cent) , imported French nuclear, Â biomass, hydro, wind and solar. Â Nuclear may be low emission or low carbon but it is not a renewable.
Many of the other newspapers are regurgitating almost identical content that has all the hallmarks of a press release. As usual, hardly any of them give a link to the original report but most do say it is a collaboration between Drax and Imperial College London. If you want to see more details or the full report then you have to head off to your favourite search engine to hunt it down.  It can be found on the Drax Electric Insights webpage. Chunks of the report can be read online (click on Read Reports near the bottom of the homepage) or you can download the whole thing as a PDF. There is also an option on the Electric Insights homepage that enables you to explore the data in more detail.
This just leaves the question as to where the FaceBook version of the headline came from. Â I suspected that a separate and very different headline had been specifically written for social media. I tested it by copying the URL and headline of the original article using a Chrome extension and pasted it into FaceBook. Sure enough, the headline automatically changed to the misleading title.
To see exactly what is going on and how, you need to look at the source code of the original article:
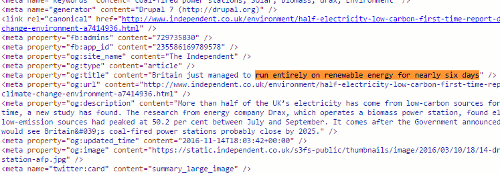
Buried in the meta data of page and tagged “og:title” is the headline that is displayed on FaceBook. This is the only place where it appears in the code. Â The “og:title” is one of the open graph meta tags that tell FaceBook and other social media platforms what to display when someone shares the content. Thus you can have totally different “headlines” for the web and FaceBook that say completely different things.
Compare “Britain just managed to run entirely on renewable energy for six days” with “Half of UK electricity comes from low-carbon sources for first time ever, claims new report” and you have to admit that the former is more likely to get shared. That is how misinformation spreads. Always, always read articles in full before sharing and, if possible, try and find the original data or report. It is not always easy but we should all have learnt by now that we cannot trust politicians, corporates or the media to give us the facts and tell the full story.
Update: The original press release from DRAX “More than 50% of Britain’s electricity now low carbon according to ground-breaking new report“