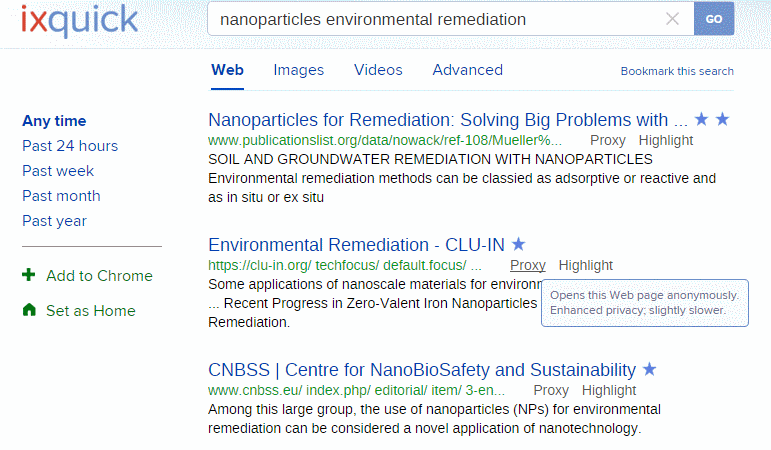
Two of the services I cover in my workshop for researchers on alternatives to Google are Carrot Search and eTools.ch, and recently one of the people who had attended the session in April asked me to confirm what Carrot Search used  to provide its main results. Strictly speaking, neither Carrot Search nor eTools are Google free: eTools is a metasearch tool that has Google as one of its sources and Carrot Search uses eTools for its web search. At the start of the year, Carrot Search offered 7 options for searching under tabs across the top of the search screen including Web, “wiki”, Bing, News, Images, PubMed and Jobs. Web search used eTools.ch to provide the results.
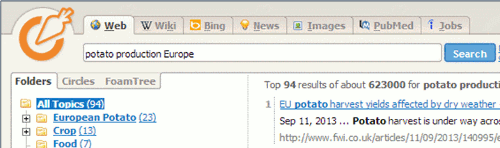
The range of options has now been reduced to just three: the more transparently labelled eTools Web Search, PubMed and Jobs.
This makes sense as the number of accesses to Bing via the api was always limited and I could never get the news or images options to work. eTools in any case is a metasearch engine covering 17 tools including Google, Bing and Wikipedia so the extra Carrot Search tabs did seem to be unnecessary. The full list can be seen on the eTools home page.
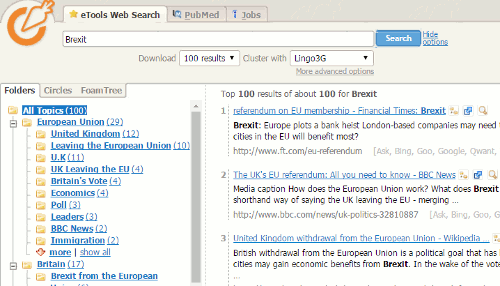
This is where it gets interesting. It appears that Carrot Search does not just copy the results from a search on eTools.  I ran a search on Brexit in Carrot Search and compared the results from eTools Worldwide and eTools United Kingdom. All of the sets  were different so Carrot Search must be doing some additional analysis and processing.
Carrot Search doesn’t just list the results but also organises them into topics or Folders that are displayed on the left hand side of the screen. These can be a useful way of narrowing down your search.
Carrot Search offers two other ways of displaying results: Circles and Foam Tree.
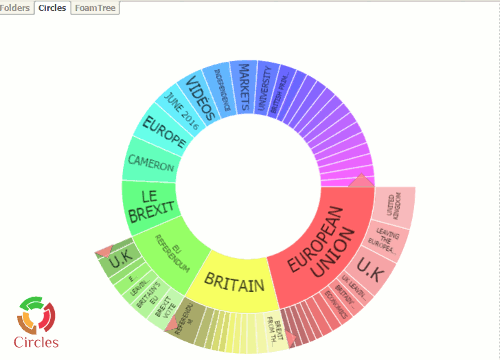
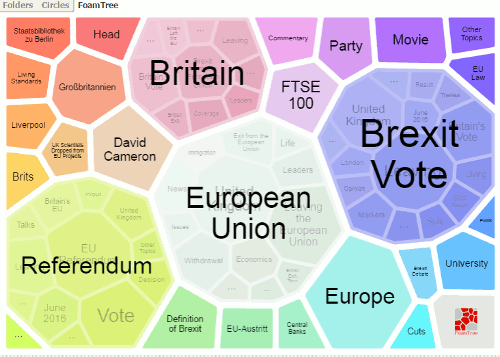
Both show the density of terms in the top 100 results and allow you to click on an area to add the term or phrase to the search.  In addition I am finding that the Foam Tree is an interesting way of monitoring changes in news coverage and social media discussions on a topic, product or company. Yesterday, when I ran the search on Brexit, there was an area representing Theresa May.  Today, that had been replaced with one for David Cameron. I assume that is because the news coverage has been concentrating on David Cameron’s last day as Prime Minister and his last Prime Minister’s Questions (PMQ) in Parliament . Later he goes to see the Queen to officially resign as Prime Minister. Tomorrow,  with Theresa May as our new Prime Minister and a new Cabinet, the Foam Tree could have a very different structure so I shall be looking at it periodically to see if and how it reflects changes in events.
As I mentioned earlier eTools.ch, which is behind the main Carrot Search web search, is a metasearch engine covering 17 tools. It also has options to select a country from a drop down list (Worldwide, Swtzerland, Liechtenstein, Germany, Austria, France, Italy, Spain,  UK) and a language (All, English, German, French, Italian, Spanish). Either or both of these give you completely different views and opinions on a subject.
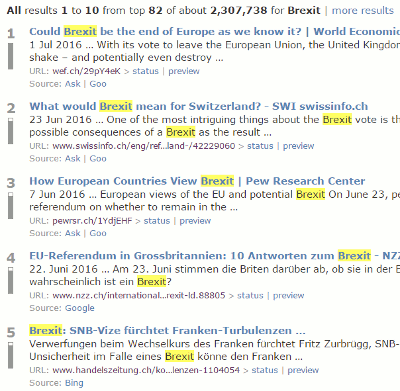
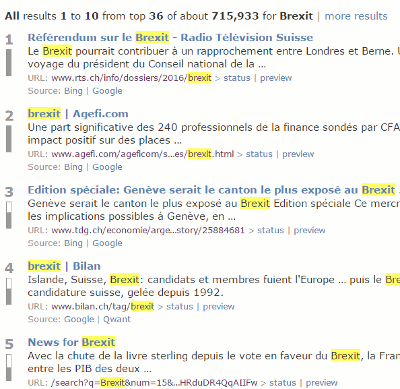
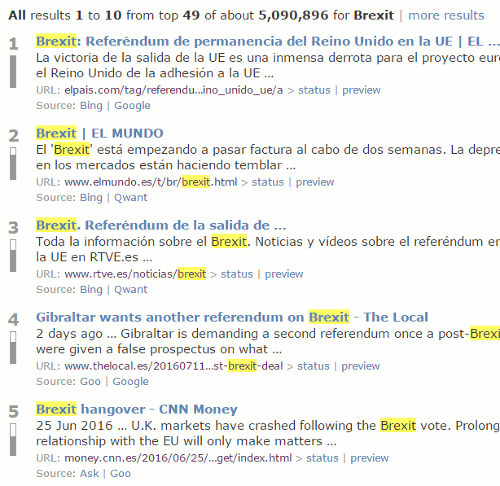
It is a convenient way of gathering a range of foreign language information, especially on European events, and is easier than searching individual country versions of Google or Bing. The disadvantages are that the range of countries and languages is limited and many of the articles will not be in English. Nevertheless, I often find it helpful at the start of a piece of research as I get a general feel for the type and range of information that is available.
Carrot Search and eTools.ch are just two of the tools that I cover in my workshop on alternatives to Google. If you are interested in finding out more, the next session is being organised by UKeiG and will be held in London on Wednesday, 7th September 2016. Further details are available on the UKeiG website.