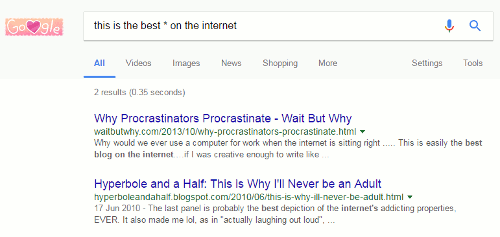
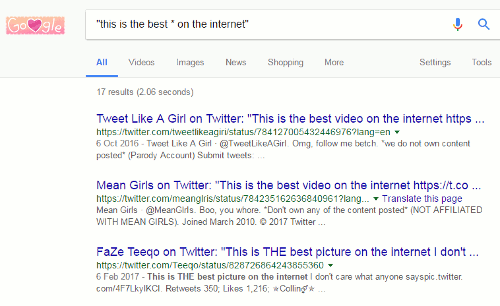
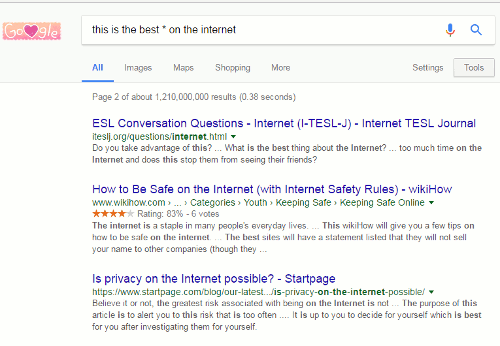
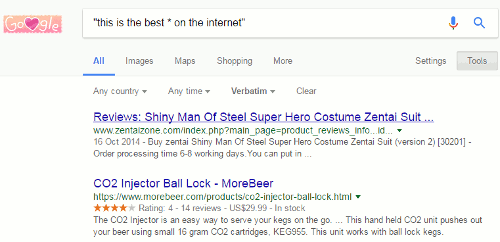
Google has been omitting terms from searches for several years. For me, the matter came to a head wayback in November 2011 (see Dear Google, stop messing with my search). Many of has had noticed it happening for a while but what suddenly made it more frustrating was that one could no longer prefix a term with a plus sign to force its inclusion in a search. Furthermore, surrounding terms and phrases with double quote marks did not always work either.
Google’s Dan Russell explained why in a comment to my blog posting:
“When you do a multi-term query on Google (even with quoted terms), the algorithm sometimes backs-off from hard ANDing all of the terms together. It’s a kind of “soft†backoff. Why? Because it’s clear that people will often write long queries (with anywhere from 5 to 10 terms) for which there are no results. Google will then selectively remove the terms that are the lowest frequency to give you some results (rather than none). Bear in mind that 99% of searchers have no idea why they’d want to hard AND, and just get frustrated when they get no results. The soft AND is a way to reduce the overall frustration and give the searcher something to examine (and with luck, a chance to reformulate their query).”
He added:
“But I see what you mean about wanting to know if there are NO hits to a given query. I’ll pass this information along to the Google design team and see if we can’t do something with this.”
Well, Google did do something about it and some weeks later Verbatim, which could be applied to your entire search and make Google run it without omissions or variations, was added as a tool. The other option that existed then, and still does, is to prefix individual terms or phrases with ‘intext:’.
If you did not use Verbatim you were still left guessing as to whether or not all of your terms or their synonyms were present in a particular document until you actually clicked on it and viewed it in its entirety. About a couple of years ago, Google started to include information on omitted terms in the results snippets by adding a “Missing: ” statement underneath the entry. At least we now had something to work with. Google has now added a search option to it. It started to appear 2-3 months ago, disappeared for a while, but now seems to be a permanent feature. It enables you to tell Google that it must include the missing term. Let’s works through the example that first alerted me to it: a search for broad beans called Eleonora and supplied by Tamar Organics.
Before you ask, the reason I did not go directly to the Tamar Organics website was because it was quicker to go via Google than to work through the seed supplier’s site search and navigation system. Also, please note that if you try this search out yourselves you will probably get very different results. When we tried this in a workshop of 20 people we ended up with 11 variations on the theme!
First, the quick and simple approach of just throwing in a few terms:
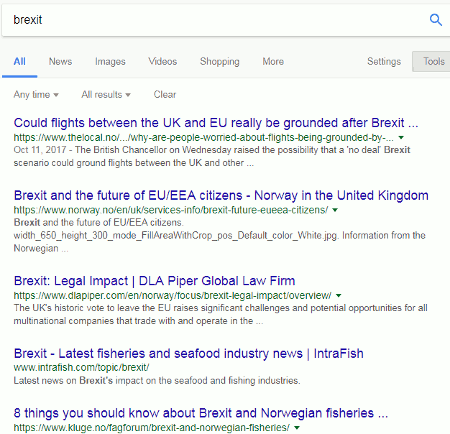
broad beans eleonora tamar organics
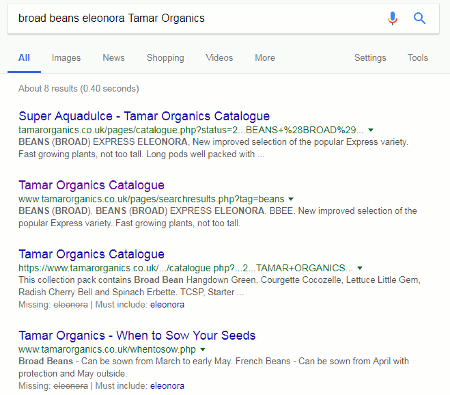
The first two results were relevant and exactly what I was looking for, but 8 results seemed a bit low especially as Google had indicated on the next two in the list that the term “eleonora” was missing. (We’ll come back to the “Must include: ” in a moment.) Going to the bottom of the results page there was the usual message that similar entries had not been displayed.

Erm… but, Google, you displayed 8 not 15 as you claim. Let’s play along, anyway, and repeat the search by clicking on the link Google gives us. This time I was given 11 results. We know that Google often gets the count wrong when using the repeat search option but I still thought that the number of results was rather low if it was omitting terms. What would happen if I decided to take Google up on its offer of “Must include: eleonora”? Two, three or perhaps just four results? I clicked on the eleonora link and …. 20,700 results!
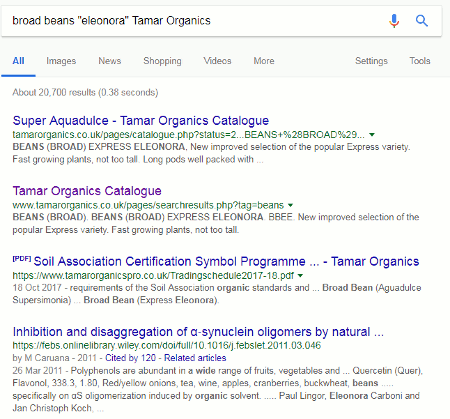
In the search bar above the results we can see that Google has put eleonora in double quote marks to force its inclusion.
The first three results were fine but when I looked in detail at the fourth document it was missing both tamar and organics, and there was no indication in the snippets provided by Google that these, or any other terms, had been omitted.
Going back to my first set of results and looking further down the list I saw that, as well as one from which eleonara was omitted, there was another that had left out both eleonora and tamar, and a third with just tamar missing.
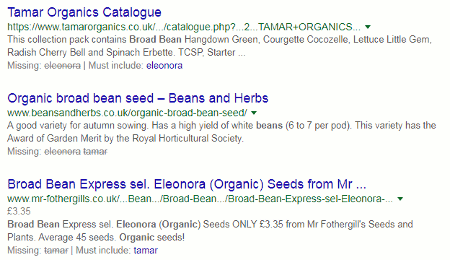
If the “Must include:” option has more than one term, you can only choose one of them. You cannot have all of them. Choosing tamar gave me  43,500 results but this time Google did tell me when eleonora was missing from the documents. Most of the results were totally irrelevant.
How would I normally deal with missing terms? I generally start off with a quick and dirty search and, unless I am looking for a particular type of document such as a presentation or industry report, I don’t always use advanced commands. I just type in the separate words and in this case I did get what I wanted at the top of the page. But what if I hadn’t?
I was interested in the variety of broad beans called Eleonora but Google was omitting it from some of the results. I could have done what Google did and use quote marks around eleonora but my experience is that Google sometimes ignores those if the number of results is low. My usual strategy is to use ‘intext:’ before the missing word, for example:
broad beans intext:eleonora tamar organics
This gave me 18,400 results with, again, most of them missing one or more terms.
Deciding to trust Google not to ignore double quote marks I changed my search to:
“broad beans” “eleonora” “tamar organics”
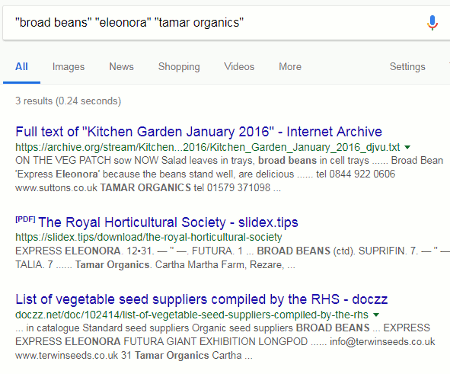
This time it was just 3 results, and when I repeated the search to include the omitted results I saw 5 but nothing from the Tamar Organics website itself. The reason for this was the presence of the phrase “broad beans” in the search string. Looking at the results in my very first search, I saw that Google was picking up the phrases “broad bean” and “beans (broad)” so I was now missing out on the top and most relevant results. A reminder that one needs to think very carefully about how and in what order search terms may appear in documents before applying phrase searching.
For comparison I applied Verbatim to the original quick and dirty search and got 411 results. The main problem with that set was that Tamar and Organics were appearing in the documents separated by several words or even sentences. When I applied Verbatim to the search string:
broad beans eleonora “Tamar Organics”
I was presented with a respectable list of 18 relevant results.
So, is the “Must include:” option worth using? It is quick and easy to apply, especially on a mobile device and I suspect that is why it has been introduced. However, it all starts to get very messy and complicated if you try to use it on subsequent sets of results. When I’m searching on my laptop, or on a desktop, I sometimes try the link but if that set of results is disappointing and Google drops a different selection of terms I go back to my practice of using intext and/or Verbatim. I also try double quotes around terms and phrases but my experience is that that Google still occasionally ignores them. It is entirely up to you which approach you use. How well each works does vary from one search to another, and on whether or not you are allowing Google to adjust results according to your search history and behaviour. The important thing is to be aware of the options available to you and to be willing to experiment.