Locating images that can be re-used, modified and incorporated into commercial or non-commercial projects is always a hot topic on my search workshops.  As soon as we start looking at tools that identify Creative Commons and public domain images the delegates start scribbling. Yes, Google and Bing both have tools that allow you to specify a license when conducting an image search but you still have to double check that the search engine has assigned the correct license to the image. There may be several images on a webpage or blog posting each having a different copyright status and search engines can to get it wrong. Flickr’s search also has an option to filter images by license and there are sites that only have Creative Commons photos, for example Geograph.  But the problem is that you may have to trawl through several sites before you find your ideal photo.
Creative Commons has just launched a new image search tool that in theory would save a lot of time and hassle.  You can find some background information on the service, which is still in beta, at Announcing the new CC Search, now in Beta. The search screen is at http://ccsearch.creativecommons.org/.
The Creative Commons collections are currently included in the search come from the Rijksmuseum, Flickr, 500px, New York Public Library and the Metropolitan Museum of Art. Â You can search by license type, title, creator, tags and collection.
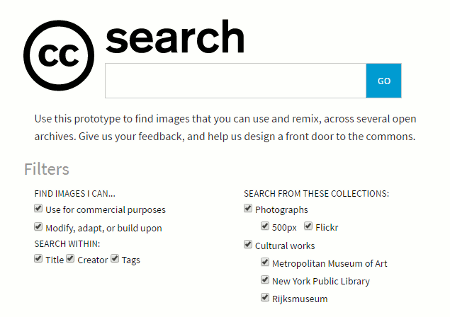  As well as search there are social features that allow you to add tags and favourites to objects, save searches, and there is a one-click attribution button that provides you with a pre-formatted text for easy attribution. There is also a list creation option. To make use of these functions you need to register, which at present can only be done via email.
 As well as search there are social features that allow you to add tags and favourites to objects, save searches, and there is a one-click attribution button that provides you with a pre-formatted text for easy attribution. There is also a list creation option. To make use of these functions you need to register, which at present can only be done via email.
I started with a very simple search: cat
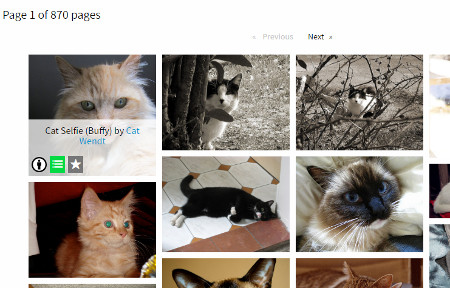
Hover over the image and you have options to Save to a list and to favourite it. It will also show you the title of the image and who created it. Click on the image and you are shown further information including tags together with a link that takes you to the original source.
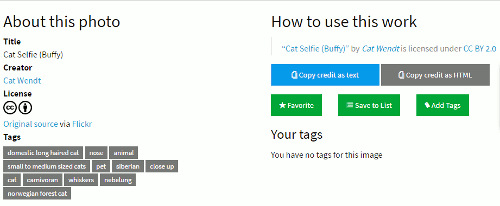
So far, so good although I did think it rather odd that the image should have tags for both norwegian forest cat and nebelung but assumed that perhaps the cat was a cross between the two.
I decided to narrow down the search to norwegian forest cat, and this is where things started to go very wrong. There were a handful of cats but the rest seemed irrelevant. I put the terms inside quotation marks “norwegian forest cat”. It made no difference.

I had a look at one of the non-cat images and the reason it had been picked up was that the creator called themselves Norwegian Forest Cat! So I unticked the options on the search screen for creator and title, leaving just the tags.  At least the results were now cats  but most did not look anything like norwegians.

I looked at the tags for one of the short haired mogs.
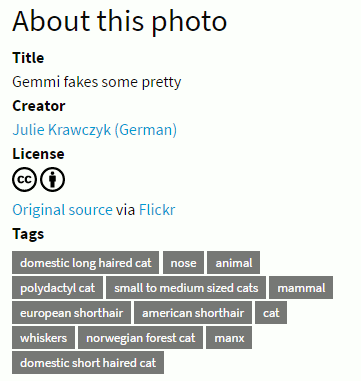
It seems that this is a very special creature. It is both a domestic long haired cat and a domestic short haired cat, a norwegian forest cat and a manx, a european shorthair and an american short hair. Â The creator of this photo must have had a brainstorm when allocating the tags, or perhaps Flickr’s automatic tagging system had kicked in? It does sometimes come up with truly bizarre tags. Â I clicked through to Flickr to view the original.

The original tags were very different. The two sets had only cat, pet, and animal in common. I have no idea where the tags on the CC photo page had come from and could not find any information on how they had been assigned. Â This was repeated with all of the dozen images that I looked at in detail.
I decided to give up on cats and try one of my other test searches: Reading Repair Cafe. I know that there are about 75 images on Flickr that have been placed in the public domain. I know that because I took them. To make it easier on CC Search I choose to search titles and tags, and just the Flickr Collection. The results were total rubbish.
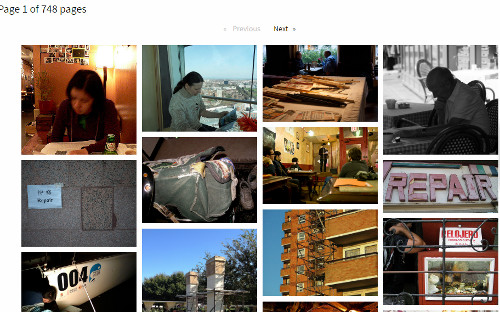
Looking at the details of the photos it became clear that CC Search is carrying out an OR search. Phrase searching did not work and using AND just created a larger collection of irrelevant images. (I confess I gave up after trawling through the first 12 pages). After the cat experience I checked the tags on a few photos but no sign of  Reading Repair Cafe anywhere.
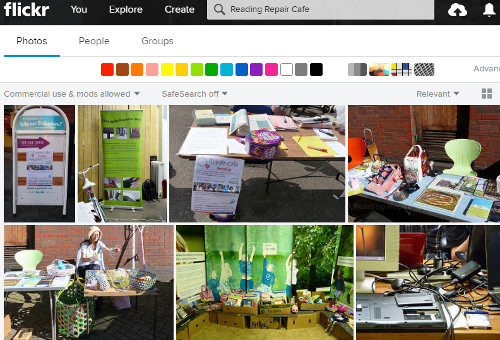
A search on Flickr and using the license filter worked a treat:
Google did a pretty good job too but to get perfect results I had to do phrase search. Â (Note: as this is a regular test search of mine, I signed out of my Google account and went “Incognito” to stop Google personalising the results. )
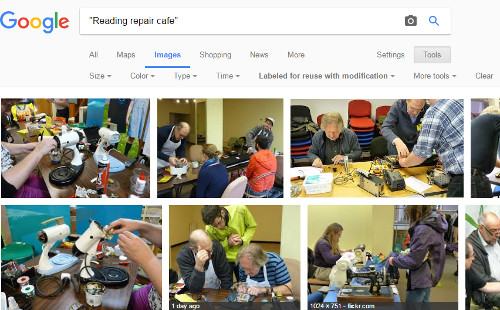
Bing also did an excellent job at finding the photos.
Admittedly, CC Image Search is a prototype and in beta so one would expect there to be a few glitches. However, glitches seem to be the norm. I ran several more tests and the main stumbling block is that it combines terms using OR. There is no other option or any commands one can use to change that. My second concern is where on earth do the tags on the CC Search photo pages come from? Most of them do not appear on the original source page and many are completely wrong. I’m afraid it is back to the drawing board for CC Search.