Yesterday, I was in Manchester leading a workshop on search techniques and business information. As well as looking at sources of information we went through some advanced search techniques, so the the top tips that the participants suggested at the end are an interesting mix of business sites and search commands.
1. DomainTools http://www.domaintools.com/
If you want to find out who is behind a web site try Domain Tools. Type in the URL of the web site under the Whois Lookup tab and DomainTools will look for details of who owns it in the domain name registries. However, if the owner of the site really does not want to be identified they may hide behind an agent or a service such as http://privacyprotect.org/.
2. Personalise Google news  and web search for location
Personalisation of search results is not always a bad thing. Google tries to work out your location from your IP address but it does sometimes get it wrong. Or you may want to specify a more precise location so that Google gives priority to content more directly relevant to you. Run a web search and then click on the cog wheel in the upper right hand area of the screen. Select ‘Search settings’ from the drop down menu. On the the next page select ‘Location’ from the menu on the left hand side and enter a location in the box provided.
In Google News, click on the cog wheel in the upper right hand area of the page. You should then see options on the right hand side for personalising topics and below those an ‘Advanced’ link. Click on the link and on the next page go to the ‘Create a custom section’ on the right hand side of the screen. Under ‘Add a local section’ you can enter a town, city or post code.
3. Company Check and Company Director Check
http://companycheck.co.uk/ and http://company-director-check.co.uk/
These related sites repackage data from Companies House and offer access to a lot of it free of charge, although you will have to register to some of it. Company Check provides 5 years of figures and graphs for Cash at Bank, Net Worth, Total Current Liabilities and Total Current Assets. You can also download accounts, and monitor a company for financial changes or for when new accounts are filed. The directors are listed and you can click through on a name to view their record on Company Director Check and see details of current and past directorships. Credit and risk reports are priced.
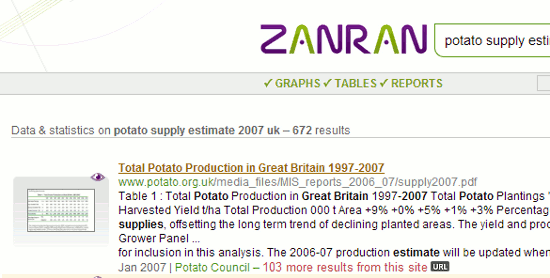
4. Zanran http://zanran.com/
This is a search tool for searching information contained in charts, graphs and tables of data and within formatted documents such as PDFs, Excel spreadsheets and images. Enter your search terms and optionally limit your search by date and/or format type. Zanran comes up with a list of documents that match your criteria with thumbnails to the left of each entry. Hover over the thumbnail to see a preview of the page containing your data and further information on the document. If you click on the title to view the whole document you may have to register (free of charge) as the title link sometimes takes you to copies of the indexed documents that are stored on Zanran. If you prefer to go to the original document click on the URL button next to the summary of the page in the results and click on the link that is then revealed. Unfortunately, you may see “page not found†especially if it is on a UK government department web site. Many of these have now been closed and their content archived making it difficult to track down the document.
5. intext:
Google’s automatic synonym search can be helpful in looking for alternative terms but if you want just one term to be included in your search exactly as you typed it in then prefix the word with intext:. For example UK public transport intext:biodiesel. It also stops Google dropping that term from the search if it thinks the number of results is too low.Â
6. filetype: to search for document formats or types of information
For example PowerPoint for experts or presentations, spreadsheets for data and statistics, or PDF for research papers and industry/government reports. Include filetype immediately followed by a colon (:) immediately followed by the file extension in your search strategy.
For example
waste vegetable oil energy generation filetype:pptx
Note that filetype:ppt will not pick up the newer .pptx so you will need to run searches on both. You will also need to look for .xlsx if you are searching for Excel spreadsheets and .docx for Word documents. The Advanced Search screen file type box does not search for the newer Microsoft Office extensions.
7. Google Finance for historical share prices
https://www.google.co.uk/finance
As well viewing historical graphs for share prices you can download the data as a spreadsheet. The data goes back to 1999 but you can only download one year at a time. You can change the date ranges in the boxes above the table on the Historical prices page. You can also specify a much shorter time span than a year, or put the same date in both boxes if you want a price for just one particular day. To access the data, first search for your stock on the Google Finance home page. Then from the menu on the left hand side of the screen select ‘Historical prices’.
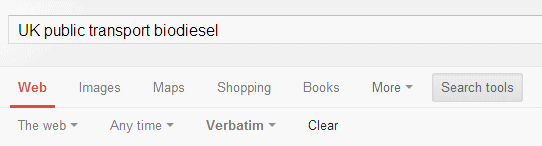
8. Verbatim
Google automatically looks for variations of your terms and no longer looks for all of your terms in a document. If you want Google to run your search exactly as you have typed it in, click on the ‘Search tools’ in the menu above your results. A second menu will then appear. Click on ‘All results’ and then Verbatim at the bottom of the drop down menu.
9. ‘Clear’ your search options when you start a new search
If you use the menus above your results to refine your search, for example by using Verbatim or Translated foreign pages, use the ‘Clear’ option to return to the Google default. Otherwise your choices will be applied to the next search.
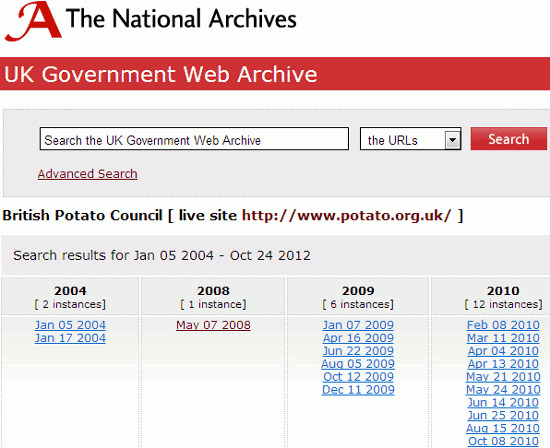
10. Disappearing sites and documents
Web sites close down, documents are deleted, and industry guidelines and standards are superseded. If you know the URL of where the document or page used to be try the Internet Archive Wayback Machine (http://archive.org/). Type in the URL of the page or document in the box next to the ‘Take Me Back’ button and click on the button. If it is in the database you should then see a calendar showing the snapshots and dates that are available. For UK government web sites a similar service is available at http://www.nationalarchives.gov.uk/webarchive/.
If you do not have an old URL or even a title of the document then it is time to start hunting around to see if it has been archived by a different web site. One of the workshop participants gave the example of trying to track down old engineering specifications and lapsed industry guidelines on deep sea oil exploration. The standard Google search techniques were not working. Thinking that Norwegian oil companies have a lot of expertise in this area, they changed the strategy to searching Norwegian web pages and used Google’s ‘Translated foreign pages’ search option (Click on ‘Search tools’ in the menu above the results, then ‘All results’ and select ‘Translated foreign pages’. Archive copies of the original documents, which were in English, were found!