Update: On further investigation the example given below is not Google rewriting
webpage titles (see the comments section). However, Google has said that they
do rewrite under certain circumstances so please let me know if you come across
any good examples.
Most of us are used to Google rewriting our searches and personalising results and know how to stop Google doing it, but Google also rewrites the titles of some pages on the results page. This is something that I and my colleagues have noticed on and off for a while but it is now official (See Google’s Matt Cutts: Why Google Will Ignore Your Page Title Tag & Write Its Own http://searchengineland.com/googles-matt-cutts-look-title-match-query-190039).
According to the article Google checks that the title of a page is relatively short, a good description of the page and relevant to the query. If the existing page title fits those criteria then Google leaves it alone. If not then Google may use other content on the page such as H1 content, anchor text links pointing to the page and/or use the Open Directory Project. The aim, Matt Cutts says, is to ensure that the title helps a user assess whether or not the page has the information they are looking for.
During a search workshop I was running last week, one of the participants came across an example of what we think was a rewritten page title. Their search was mindfulness in school as crime prevention uk site:ac.uk. Top of the list was the home page of JournalTOCs and the title that Google gave was “Implementing mindfulness and yoga in urban schools: a…”.
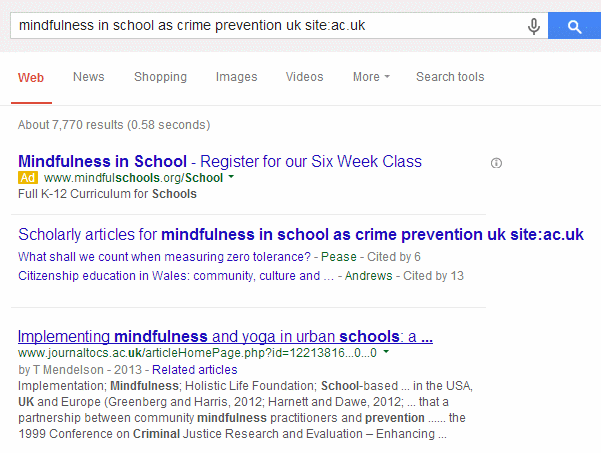
This looked relevant to the search but clicking on the link took us to the home page of JournalTOCs where none of the original search terms were mentioned.

The source code of the page showed that the original title is simply JournalTOCs.
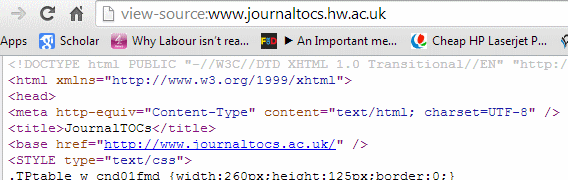
Did JournalTOCs have the keywords on an earlier version of its homepage that is currently in Google’s cache or did Google rewrite the search as well as the title of the page? When I tried to view Google’s cached copy of the page I got a 404 error!

I reran the search and applied Verbatim to it. There were four JournalTOCs pages in the first 100 results that were relevant but none matched the title that Google gave in the original results. I ran a search on that title in JournalTOCs but found nothing. Searching elsewhere I found that the article does exist. Also, the URL of the JournalTOCs page in the original results seems to include a reference to an article page, so I am not sure what is going on here. Did Google really rewrite the title? Or was the article once listed in JournalTOCs but no longer there and Google’s cached copies of JournalTOCs are out of date? Either way Google’s results were inaccurate, misleading and very confusing.
I don’t think it’s Google, rather it seems to be JournalTOCs. They auto-redirect from a JournalTOC article record page to the original journal page, and have somehow managed to fool the Googlebot into indexing that ‘bounced to’ page. I’m not sure that Google will be happy about the use of that sort of SEO-style tactic, once they discover what’s happening. As for your actual problem, perhaps you have a redirect blocker addon in your browser – so merely end up at the JournalTOCs home page? On clicking on a result I see the redirected page almost immediately, and not a JournalTOCs page.
You are right. It’s a JournalTOCs issue and not Google rewriting the title. I have since run other searches looking for papers on just the JournalTOCs website and all Google’s links take me to the correct article page. It was just that one particular paper that redirected us to the home page. The problem that I reported above happened in an IT suite where I was not using my own computer, but I could replicate it for that one paper on my laptop when I got back home – no redirect blockers invloved. I tried searching for that specific paper on JournalTOCs but it appears to have gone, although it can be found elswhere on the web. Not sure, though, why Google’s cached copy came up with a 404. It seems it was pure chance that we happened on the one paper that bounced to the home page and which led us to believe Google was rewriting page titles. I guess it’s back to scanning results for examples of Google’s creativity.
This is correct: “the article once listed in JournalTOCs but no longer there and Google’s cached copies of JournalTOCs are out of date”
Nobody is trying to fool the Googleboot. Google robots shouldn’t systematically generate, index and cache search queries using JournalTOCs search input box. JournalTOCs only lists the latest articles and does not store previous published articles.