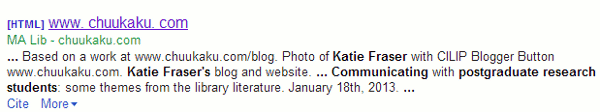| |
Tales from the Terminal RoomJanuary 2013, Issue No. 107 |
| |
|
|
|
|
|
|
Please Note: This is an archive copy of the newsletter. The information and links that it contains are not updated.
|
|
Tales from the Terminal Room ISSN 1467-338X Tales from the Terminal Room (TFTTR) is an electronic newsletter that includes reviews and comparisons of information sources; useful tools for managing information; technical and access problems on the Net; and news of RBA's training courses and publications. Many of the articles will have already appeared on Karen Blakeman's Blog at http://www.rba.co.uk/wordpress/ Tales from the Terminal Room can be delivered via email as plain text or as a PDF with active links. You can join the distribution list by going to http://www.rba.co.uk/tfttr/index.shtml and filling in the form. You will be sent an email asking you to confirm that you want to be added to the list. TFTTR is also available as an RSS feed. The URL for the feed is http://www.rba.co.uk/rss/tfttr.xml In this issue:
Search toolsGoogle Scholar author failEight months after setting up my Google Scholar author profile and claiming my papers I have received my first alert. If you only use Google Scholar (http://scholar.google.com/) to search for papers you may not be aware that if you have published papers you can set up a Google Scholar author profile and add those papers to your profile. Google then creates a page showing a graph of when and how often your papers were cited and generates an H-index and i10-index for you. This only covers the papers that Google Scholar has in its database and there are serious gaps in its coverage for some sectors. On the other hand, it does sometimes include articles, web sites and blog postings that are not peer reviewed in the conventional way. This can be a good thing because it may pick up some very useful grey literature. It can be a bad thing because it is possible to fool Scholar into adding a paper of dubious quality by mimicking the structure of an academic paper title and author names in large font, affiliation, abstract, keywords, list of references etc. Another feature of Scholar is that you can create alerts for keyword searches, new papers by an author or new citations to their articles. Needless to say I have set up alerts on my own name! Sadly, until last week I had received nothing so had to assume that no-one was interested in or citing my papers. Or perhaps the alerts do not work? Whatever the reason, I was delighted that at last someone had mentioned me in some way in an article. Clicking through to the item, though, led me to Katie Fraser's blog and Communicating with postgraduate research students: some themes from the library literature (http://www.chuukaku.com/blog/2013/01/communication-with-pgr.html). Was I mentioned or cited in the posting? No, but my own blog was listed in her blogroll to the left of the article. Having got over the disappointment I turned my attention to working out why Scholar had picked up this particular post. Why wasn't I receiving alerts every time Katie updated her blog? The answer appears to be at the end of the posting in question: Katie has provided a list of references.
Another factor, I thought, might be that Katie has an author profile and claimed her papers but I could not see it anywhere in her profile. On further investigation, and unfortunately for Katie, Google Scholar is unaware that she is the author of this article. It appears that it is someone called MA Lib.
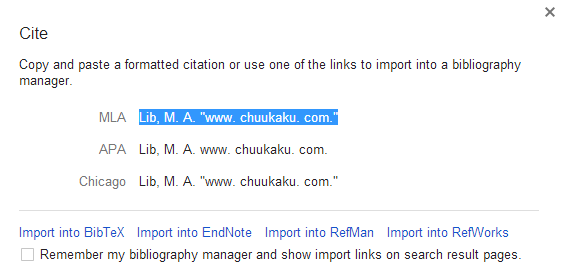
This was confirmed when I clicked on the Cite' option. This presents you with formatted citations that you can cut and paste into an article or import into a bibliography manager. The author is definitely MA Lib.
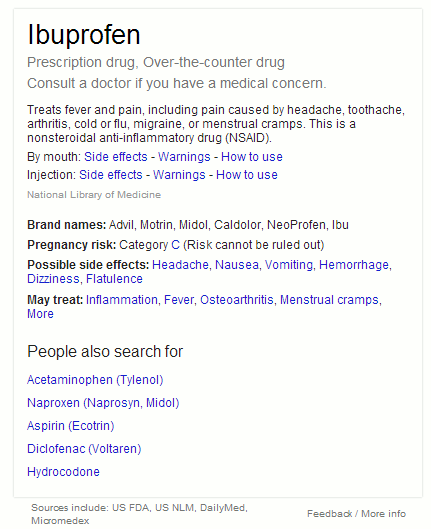
Google Scholar has failed to recognise Katie Fraser as the author and has decided that the MA Lib link in the side menu of her blog is a person's name. There are many similar examples and it is well known that Scholar is unreliable when it comes to identifying authors. Peter Jacso has written several articles detailing Scholar's shortcomings in this area. (1, 2, 3, 4). Many of his articles are available as pre-prints (5). What this means for Katie is that although Google Scholar believes her blog posting (6) is worthy of inclusion in its database it is not listed in her author profile and does not contribute towards her h or i10-index. And in case you are wondering, yes I have appended references to this article on my blog to see if Google regards it as scholarly literature and adds it to the Scholar database Update: Katie Fraser has now claimed the posting for her profile but the Google Scholar database has not yet been updated to reflect this. References (1) Jacsó, Péter. Metadata mega mess in Google Scholar. Online Information Review 34.1 (2010): 175-191. (2) Jacsó, Péter. Newswire Analysis: Google Scholar's Ghost Authors, Lost Authors, and Other Problems [Online] 24 September 2009 [Accessed 4 February 2013.] http://www.libraryjournal.com/article/CA6698580.html (3) Jacsó, Péter. Google Scholar Author Citation Tracker: is it too little, too late? Online Information Review 36.1 (2012): 126-141. (4)Jacsó, Péter. Using Google Scholar for journal impact factors and the h-index in nationwide publishing assessments in academiasiren songs and air-raid sirens. Online Information Review 36.3 (2012): 462-478. (5) Jacso Savvy Searching Columns, Online Information Review http://www2.hawaii.edu/~jacso/savvy-mcb.htm [ Accessed 4 February 2013] (6) Lib, M. A. " www.chuukaku.com." Medicine search on GoogleIn November of last year Google announced that it was going to start showing a knowledge graph for searches on medicines. (Look up medications more quickly and easily on Google, http://insidesearch.blogspot.co.uk/2012/11/look-up-medications-more-quickly-and.html). I am now seeing it in my search results but only on Google.com. When I search on ibuprofen Google now gives me some key facts on the drug in a box to the right of the standard web results. The information includes indications for use, side effects, brand names, contraindications and other drugs that people also searched for. The sources it uses are the National Library of Medicine, US FDA, DailyMed and and Micromedex.
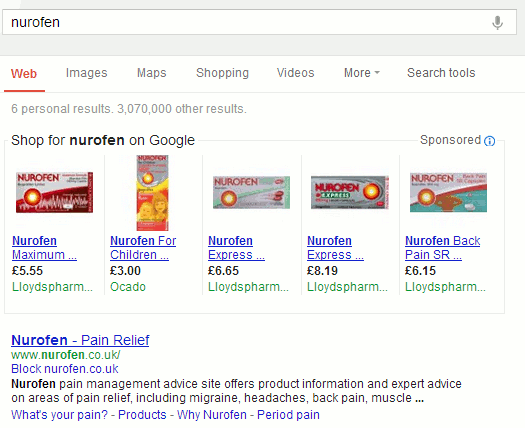
Ibuprofen is the generic name for this painkiller and is one of the names under which it is sold in the UK and many other countries. Searching on the brand name Nurofen, which is not available in the US, brings up web search results with shopping options at the top. There is no knowledge graph this time.
I played around with a few other brand names and found that if it is on sale in the US, for example Motrin, Google is able to identify the active ingredient and adds a knowledge graph to the results. So Google's new medicine search is US-centric: US brand names and US sources of information. It will be interesting to see if and how they roll it out to other countries. Meanwhile, for those of in the UK NHS Choices provides better and more detailed information on medicines at http://www.nhs.uk/medicine-guides/, and if you are interested in a drug's physical or chemical properties Chemspider (http://www.chemspider.com/) is a good starting point. Already appearing in UK Google results is the related medical conditions feature. Type in a symptom and Google lists possible related conditions at the top of the page.
If you are using Google.co.uk or are based in the UK clicking on any of the conditions in the list brings up content that is UK focused. It will be interesting to see if they do the same with the medicines knowledge graph. Search Strategies updateThere are three new articles available in the subscribers' area of Search Strategies:
Annual individual subscription rates are £48/year (£40 + £8 VAT). Multi-user and corporate rates are available on request. For further details contact Karen Blakeman [email protected]. To purchase a subscription go to http://www.rba.co.uk/search/purchase.shtml A list of free and subscription content is at http://www.rba.co.uk/search/ Free content includes:
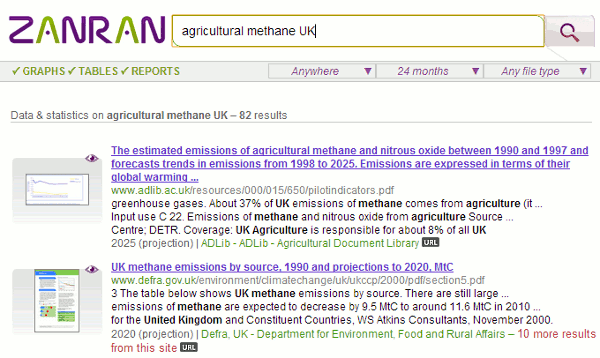
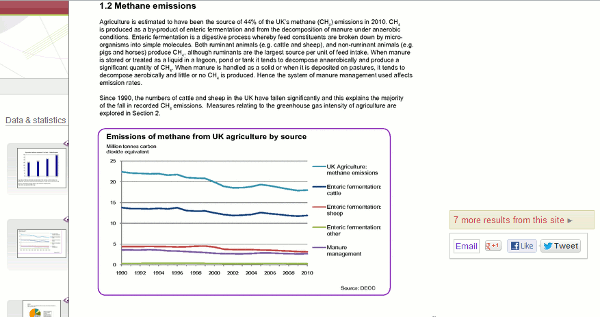
Zanran great for data in tables, charts and graphsI regularly mention Zanran (http://www.zanran.com/) in my workshops on search and business information, and it often finds its way into the Top Tips compiled by the delegates at the end of the day. Zanran is not a Google alternative. Rather than search the text of web pages it extracts and indexes numerical data presented as tables, charts and images in PDF reports, spreadsheets and ordinary web pages. You can simply type in your search terms but there are additional options for narrowing down the search by location of the web server, specifying an individual site, selecting a time period and limiting by file type. The results page lists the files it has found with an extract highlighting the content containing your terms. In this example I am looking for data on agricultural methane emissions in the UK.
To the left of each entry is a thumbnail. Moving the cursor over the thumbnail brings up a preview of the page containing the relevant chart, table or image. This enables you to immediately assess the relevance of the data without having to download and go through a lengthy document. If you click on the thumbnail or the title to view the whole document you have to register (free of charge) as copies of the indexed documents are stored by Zanran. If you prefer to go to the original document click on the URL button attached to the summary of the page and click on the link that is then revealed. Unfortunately, you may see page not found especially if it is on a UK government department web site. Many of these have now been closed and their content archived making it difficult to track them down. Registering with Zanran is by far the easier option. Also, rather than deluge you with documents from a single site, as Google all too often does, Zanran gives you a link telling you if and how many other results are available on a site. How does it compare with Google? Well, Google did come up with relevant results for my search but I had to spend a lot of time ploughing through them to identify the best documents. And Google did not pull up in the first 100 results the very useful archived UK government documents that Zanran gave me. If you are looking for data or statistics Google still does a very good job but I recommend you also run a search in Zanran. It may well come up with a real gem, as it often has for me. Forthcoming workshopsI am running three workshops in April on business information and search. All three have a practical element so that you can try out resources and techniques for yourself. Introduction to Business Research This is being organised by TFPL and will be held in London on Thursday, 18 th April. This course provides an introduction to many areas of business research including statistics, official company information, market information, biographical information and news sources. It will cover explanations of the jargon and terminology, regulatory issues, assessing the quality of information, primary and secondary sources. Further information is available on the TFPL web site at http://www.tfpl.com/services/coursedesc.cfm?id=TR1116&pageid=-9&cs1=&cs2=f Business information: key web resources This is also being organised by TFPL in London and is being held on Friday, 19 th April. This workshop looks in more detail at the resources that are available for different types of information, alerting services and free vs. fee. It also covers search strategies for tracking down industry, market and corporate reports. Further information is available at http://www.tfpl.com/services/coursedesc.cfm?id=TR945&pageid=-9&cs1=&cs2=f Make Google behave: techniques for better results This is a very popular workshop and is being organised by UKeiG. It is being held in Manchester on Tuesday, 30 th April. Topics include:
The workshop will be repeated in London on Wednesday, 30 th October. Details and booking information are on the UKeiG website at http://www.ukeig.org.uk/trainingevent/make-google-behave-techniques-better-results-karen-blakeman Twitter NotesThe following are some of my recent tweets and retweets. They are selected because they contain links to resources or announcements that may be of general interest. I have unshortened the shortened URLs 8th January RT @sengineland: Google Is Hiring Someone To Find Ways To Make You Want To Search While Signed-In by @rustybrick http://searchengineland.com/google-is-hiring-someone-to-find-ways-to-make-you-want-to-search-while-signed-in-144523 16th January RT @sengineland How The New Facebook Search Is Different & Unique From Google Search by @dannysullivan # graphsearch http://searchengineland.com/facebook-search-not-google-search-145124 21st January MT @Andy_Tattersall : The funky video promo for # mmit2013 Cloudbusting http://www.youtube.com/watch?v=AkcDfY5nYZo&feature=youtu.be 24th January RT @infoforenergy: Interactive map by the Guardian plotting outdoor air pollution worldwide: http://worldbank.tumblr.com/post/41207322814/outdoor-air-pollution-mapped-by-city Shambrarians please note RT @ScottishBIS The world's fastest growing beer markets (datagraphic) http://blog.euromonitor.com/2013/01/the-worlds-fastest-growing-beer-markets.html 29th January MT @theREALwikiman Hashtags useful for sharing resources on a subject, Guide for people new to Twitter http://thewikiman.org/blog/?p=979 TFTTR Contact InformationKaren Blakeman, RBA Information Services ArchivesTFTTR archives: http://www.rba.co.uk/tfttr/archives/index.shtml Subscribe and UnsubscribeTo subscribe to the newsletter fill in the online registration form at http://www.rba.co.uk/tfttr/index.shtml To unsubscribe, use the registration form at http://www.rba.co.uk/tfttr/index.shtml and check the unsubscribe radio button. Privacy StatementSubscribers' details are used only to enable distribution of the newsletter Tales from the Terminal Room. The subscriber list is not used for any other purpose, nor will it be disclosed by RBA or made available in any form to any other individual, organisation or company.
|
| This page was last updated on February 6th, 2013 | Copyright
© 2013 Karen
Blakeman. |