| |
Tales from the Terminal RoomNovember 2006, Issue No. 74 |
| |
|
|
|
|
|
|
Please Note: This is an archive copy of the newsletter. The information and links that it contains are not updated.
|
Tales from the Terminal Room ISSN 1467-338X Tales from the Terminal Room (TFTTR) is a monthly newsletter, with the exception of July and August, and November and December, which are published as single issues. TFTTR includes reviews and comparisons of information sources; updates to the RBA Web site Business Sources and other useful resources; dealing with technical and access problems on the Net; and news of RBA's training courses and publications. Tales from the Terminal Room can be delivered via email as plain text or as a PDF with active links. You can join the distribution list by going to http://www.rba.co.uk/tfttr/index.shtml and filling in the form. You will be sent an email asking you to confirm that you want to be added to the list. TFTTR is also available as an RSS feed. The URL for the feed is http://www.rba.co.uk/rss/tfttr.xml . In this issue
Search ToolsWindows Live new(ish) search featuresThe image search in Windows Live is not exactly new but I have only just spotted the significance of the scroll bar on the right hand side of the results screen. Scroll down and you'll quickly see that Live lets you go through all of your results on one single page. Much better than the usual default 10 or 20 displayed in the other search engines. Also, if you search for a person a list of related people appears on the right hand side of the screen. The Video search option seems to come and go from day to day. When It is there and working it comes up with what I consider to be sensible results, but then I am usually looking for business related files such as TV interviews or podcasts on a company's annual results from CEOs. There are occasions, though, when it keels over completely. Just remember that it is still in beta. The linkfromdomain command definitely is new. This gives you a list of links to other pages from your specified domain. For example linkfromdomain:rba.co.uk. This can be useful if you have a trusted source of information and want to see what other sites they recommend or link to. It can also be used as a means of assessing the bias of a site so that you can see the diversity, or lack of it, in the pages that are 'cited'. Undocumented Yahoo commandsIn his pre-conference Internet Librarian workshop on power searching, Greg Notess highlighted some of the undocumented Yahoo commands that the search engine inherited when it acquired the Inktomi database. Former Hotbot users may remember some of them. For example the region command enables you to restrict your search by continent or region, for example region:europe. The list that Greg gave included: region:africa Another command is originurlextension. If you have ever tried to limit your search in Yahoo by filetype you will have discovered that you have to use the box and drop down list on the advanced search page. The filetype command only finds pages that contain links to documents in the specified format; your search terms will appear in the web page but not necessarily in the document itself. The equivalent filetype command in Yahoo is originurlextension, for example originurlextension:pdf . These and other Yahoo commands can be found on Greg Notess's site at http://www.searchengineshowdown.com/features/yahoo/ Unclustering resultsAnother command that Greg Notess came up with at his ILI pre-conference workshop in October enables you to 'uncluster' pages from the same site in Google results. Normally Google shows you just two pages from the same site regardless of how many contain your search terms. You have to click on the 'More results from..' link to see them all. To uncluster the results, run your search as normal and then add &filter=0 to the end of the URL of the search page. In Yahoo you can uncluster results by adding &dups=1 to the results page URL. Assessing the Quality of Information: Top TipsOr: Paranoia 'r' us
Two additional general points were made in conclusion:
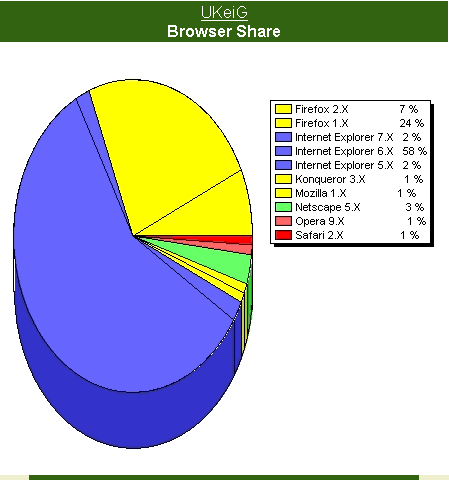
Web exceeds 100 million 'web sites'Just when you thought you had got on top of information overload, Netcraft releases their latest survey revealing that there are now more than 100 million domain/host names out there. This is an increase of 3.5 million over last month, and the accompanying graph suggests that there is no slow down in peeps wanting to set up their own domain on the Net. The report is confusing because the text refers to web sites but the graph is labelled Domains August 1995 - November 2006 and the relevant line is labelled host names. Domain names and web sites are NOT synonymous. A single web site can be set up so that several domain names point to it - until recently the UKeiG web site had 9 domain names. Also many domain names are bought but not used for an active web site. Browser Shares - October 2006The UK eInformation Group (UKeiG) have blogged their usually monthly analysis of which browsers people are using to access the UKeiG web site and blog. The figures are based on 34,294 page views in October 2006 and it comes as no surprise that IE 6 is still in the lead but with only 58% usage. Firefox 1.x comes in at number 2 with 24% and Firefox 2.x already has a share of 7%. So that makes Firefox's share a whopping 31%. UKeiG regularly reports high Firefox percentages, which is not really that surprising. UKeiG actively promotes the Firefox via its factsheets, on the wiki and in its workshops, and many visitors to the site are likely to be tech savvy readers who have control over what software they can install or are in organisations that give freedom of choice re browsers. Other browsers included Netscape 5.* (3%), IE7 (2%), IE 5 (2%), Konqueror, Mozilla 1, Opera 9 and Safari 2.
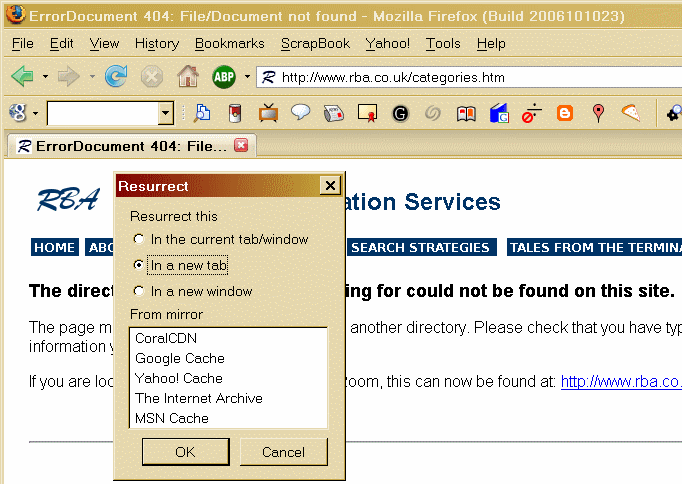
Online Information 2006Online Information 2006 starts on November 28th and runs until Thursday 30th November, at Olympia in London. There is still time to book a place at the conference and although the early-bird discount no longer applies you may be eligible for a 15% discount if you belong to one of the 'partner' organisations or associations such as CILIP or UKeiG. Further details are on the Online Information web site at http://www.online-information.co.uk/ol06/conference.html If you can't make it to the conference, there are free seminars and master classes talking place in the exhibition hall. Full programme and details are at http://www.online-information.co.uk/ol06/seminars.html Conference and seminar presentations availableMany of the presentations made at Internet Librarian International 2006, London, are now available on the ILI web site (http://www.internet-librarian.com/presentations.shtml). If you want to 'flesh out the bones', try and track down blog postings on the event. Tom Roper's blog (http://tomroper.typepad.com/ ) is a good place to start. He has neatly summarised my presentation on out-Googling Google (http://tomroper.typepad.com/tr/2006/10/internet_librar_12.html ), so worth reading it along side my Powerpoint slides which are available on the ILI web site or at http://www.rba.co.uk/ili/index.html For other blogger accounts try Technorati (http://www.technorati.com/) and use the tag ili2006. If you are interested in seeing photos of the event go to Flickr (http://www.flickr.com/) and use the tag ili2006. CILIP's East of England Information Services Group put on an excellent day covering the whole range of '2G' internet services. The Let's Get Wiki'd event included Library 2.0 and Web 2.0 (Dave Pattern from the University of Huddersfield), Mashups (Richard Wallis, Talis), Social Bookmarking and Connotea (Joanna Scott, Nature), and wikis and the semantic web (Nick Kings, BT). I finished off the day with a session on assessing the quality of collaboratively collected information. The presentations will soon be made available via the ISG web site (http://www.cilip.org.uk/specialinterestgroups/bysubject/informationservices/regions/ee). In the meantime, mine is at http://www.rba.co.uk/isgeoe/index.html Information ResourcesBlogs and RSS for competitive intelligencehttp://www.digimind.com/en/download/White_Paper_Blogs-RSS_EN_2006.pdf There is increasing awareness that blogs and RSS are an important part of competitive intelligence. This document, published by Digimind (http://www.digimind.com/), is an excellent overview and introduction to how they can be used in competitive intelligence, and includes an extensive list of references and further reading. Highly recommended if you are wondering what all the fuss is about and whether or not you should leap onto the bandwagon. Another 'must read' paper is 'RSS: the CI Professional's Best Friend' by August Jackson, Evidence Based Research. It originally appeared in Competitive Intelligence Magazine, Vol 9 Number1, Jan-Feb 2006, pages 23- 27. A PDF of the article can be found at http://homepage.mac.com/cornfed/RSSarticle.pdf . August also a podcast devoted to CI at Competitive Intelligence Podcast http://www.cipodcast.com/ Passport launched for OurProperty and PetrolPrices.comFubra, who run and maintain the OurProperty (http://www.ourproperty.co.uk/) and PetrolPrices.com (http://www.petrolprices.com/) web sites, have launched the Fubra Passport. This is a single login system that will be valid for all existing and future Fubra web sites and consists of your email address and just one password. You no longer need your user name. Fubra say that the benefits will become obvious as they launch more sites over the next few months, but no clues from them yet as to what those sites are likely to be. So far, I have been very impressed with Fubra's sites. I use regularly use OurProperty, which repackages Land Registry data, and friends and colleagues reckon that PetrolPrices, which gives details of local petrol prices, is excellent. (We gave up our car 15 years ago as an experiment and are still managing to survive and travel with out it!). Fubra also run Compare Airport Parking (http://www.airport-parking-shop.co.uk/). Gizmo of the MonthFirefox add-on - Resurrect Pages https://addons.mozilla.org/firefox/2570/ This is the prefect Firefox add-on for the dreaded 404 message, or if you want to see which version of a page the search engines have in their cache. You can try five page cache/mirrors in turn: CoralCDN, Google Cache, Yahoo! Cache, The Internet Archive and the MSN/Live Cache. The search engine caches usually only have copies going back days or, at most, weeks but the Internet Archive may have copies going back to 1996. If you have installed Firefox 2 you may need to use the Nightly Tester Tool add-on to persuade Firefox that Resurrect Pages is compatible.
Meetings and WorkshopsKaren Blakeman will be giving two free seminars as part of the seminar and master class programme at the Online Information exhibition:
Details of these and the rest of the seminar programme are at http://www.online-information.co.uk/ol06/seminars.html Workshop: Advanced Internet Search Strategies TFTTR Contact InformationKaren Blakeman, RBA Information Services ArchivesTFTTR archives: http://www.rba.co.uk/tfttr/archives/index.shtml Subscribe and UnsubscribeTo subscribe to the newsletter fill in the online registration form at http://www.rba.co.uk/tfttr/index.shtml To unsubscribe, use the registration form at http://www.rba.co.uk/tfttr/index.shtml and check the unsubscribe radio button. Privacy StatementSubscribers' details are used only to enable distribution of the newsletter Tales from the Terminal Room. The subscriber list is not used for any other purpose, nor will it be disclosed by RBA or made available in any form to any other individual, organisation or company. This publication may be copied and distributed in its entirety. Individual sections may NOT be copied or distributed in any form without the prior written agreement of the publisher. Copyright (c) 2006 Karen Blakeman. All rights reserved |
| This page was last updated on18th November 2006 | Copyright
© 2006
Karen
Blakeman. All rights reserved |